Everyone has an email account. Whether you use it for its intended purpose or not, it’s all but required to use the internet today. Most people I talk to primarily just use email to sign-up for sites, reset passwords, or get specific emails. Their mailboxes are out of control, and for OCD people like myself,…
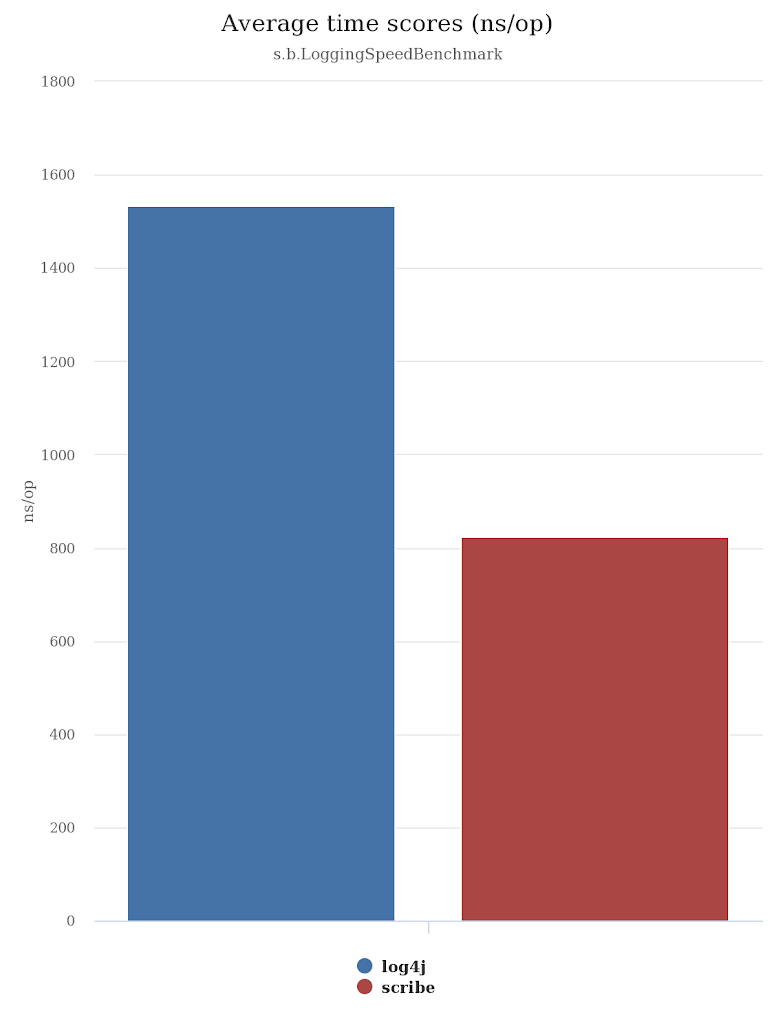
Scribe 2.0: Fastest JVM Logger in the World!
An intentionally provocative heading, but one I stand behind until someone can prove otherwise (and I welcome just that). Scribe 1.x was pretty fast (https://matthicks.com/2017/01/12/logging-performance/), but was not written with performance in mind. When I came back around and realized just how fast log4j2 is, I could see no reason why a Scala logging solution shouldn’t be…

Logging Performance
I’ve never been a fan of the setup of logging frameworks as far back as when I was a Java developer. The hassle and complexity of configuring and managing the logging framework was always a big hassle and would often create serious problems in the application if not done right. Even today in Scala it…
Publicity in Open-Source
To my relatively small number of followers, it should come as no surprise that my biggest failing is actually getting much visibility for my vast number of open-source projects I write. To that end I’ve been doing some research and asking other developers to give me some suggestions on how to get more visibility for…
Play Framework for Scala: An Evaluation
I often speak to clients and developers that are pushing the Play Framework as the ideal web framework when developing Scala web applications. I started considering why Play is the framework that people tend to settle on, especially large companies. I think there are a few reasons: It’s supported by Typesafe *cough*, I mean Lightbend….
Mobile Development Hell
I’ve been writing a pretty large mobile application for a client recently and am finally getting close to releasing it, but thought it might be worthwhile to write a little bit about the experience I’ve had. The Frameworks I expected jumping into development for Android and iOS would be fairly straight-forward. Mobile development has been…
Mocking should be Mocked
I’ve worked with and for a lot of companies over the years and with the ones that actually care about unit testing Mocking (Mockito or some other variation) typically quickly enters the scene. My argument is that in proper coding you should be able to write proper unit tests without any mock objects. I’ll go…

Nabo TV: Next Generation Media Center
For years media centers, DVRs, and video streaming sites have existed to watch TV and Movies. Over the past several years these services have stagnated. Though there are no shortage of media centers, they all seem to be doing pretty much the exact same thing. For years we have watched and longed for a more…
Why Templates Suck
The Problem I’ve been asked a lot recently about what template engine I prefer and most people seem shocked when I say that I do my best to avoid them and just generally don’t like the idea of templates. Let me first define what I mean by templates before I get into my explanation so…
Hyperscala: Web Site
I have been negligent giving proper support to Hyperscala’s public appearance and have spent the past several months working on the API itself. However, today I finally released a very basic web site at hyperscala.org: The site is incredibly basic right now and not all that pretty but it is written in 100% Hyperscala and…